29 Apr 2008 - permalink
My about page has mentioned a web based frontend for Xdebug for some time. The project has a name now: The idea for Webgrind, a spin on Valgrind, came from lack of profiling tools for PHP, particularly on OSX. Though it is possible to install kcachegrind on osx it seems overkill for many uses and is definitely not as easy as unzipping a folder to the webroot.
After sitting on the idea for some time, I spoke with Jacob Oettinger about it and he promptly started on the foundation. What we have done up to this point is far from the power of kcachegrind, but it does allow for simple profiling in the browser to locate methods and functions most in need of optimization. Plus it installs in seconds.
I have since learned that the PHP group has a suggestion for a Google Summer of Code project that replicates the features of KCacheGrind as a web frontend. It seems Chung-Yang Lee has signed up for the challenge and it will be interesting to follow his progress.
We are currently making the last changes before releasing the first version on our Google code page for Webgrind. Please let us know what you think of this and of any ideas for future features. A downloadable package will be ready on Wednesday.
13 Apr 2008 - permalink
I forgot where I first saw this amazing demonstration of a sound recording and playback technology that preserves the spatial information required for the brain to hear the location of sound sources called Cetera.
Developed by hearing aid producer Starkey Labs, Cetera apparently is not a new technology. Audiology Online has an article about Cetera from 1999 but this is the first I’ve heard about it.
Sound is recorded by two microphones placed at a distance similar to that of the human ears and further processed to mimic the acoustics of the outer ear, and the result is unbelievably real. In the illustrational recording oh a virtual haircut, the electric razor feels eerily close to your ear! To experience the effect, headphones are needed:
Sajithmr has a full transcript of the dialogue and two more recordings.
If only this technique could be used in first-person computer games they would instantly become more immersive!
26 Feb 2008 - permalink
Too good not to post, I found this gem on OSNews FocusShift comic strip page. Brilliant!

18 Jan 2008 - permalink
My last two posts have been about opening the social web and I am obviously not alone in thinking greater interoperability would benefit providers and users alike. The net is buzzing with initiatives for opening the social graph and one of the most promising is the Dataportability Workgroup.
This brilliant video explains why data portability matters:
1 Dec 2007 - permalink
Aggregating content from a variety of sources through APIs is just a small part of the task of opening the web. While it allows me (the user) to present my online activities where I choose, it lacks the social relations.
There are currently hundreds if not thousands of takes on the social net and some of them take a more open approach than others. I recently re-discovered Plaxo, a site that first set out to keep your address book up to date and know includes a mashup timeline of user’s online events on other sites. My main gripe is that it requires registration to see the profiles. A site like SecondBrain is closer to what I want (and been building on this site): A public stream of activities that I’ve chosen to share with the world.
Though many sites allow for importing contacts from other sites like Gmail, LinkedIn, finding people you know is very much a manual and tedious process. How can the social relations be implemented in an open way re-using as much as possible of what is already out there and in a format that is readable by a computer?
Using the markup defined by XFN to add relationship information to hyperlinks, it is easy to see how one could build a parser to find these tags and build a social graph, one node at a time. Tagging urls as me, I could easily list urls to various sites I use and by doing so provide further data to the parser.
Aggregating personal data from your own sources and making it available in a standard format (RSS or some other XML/* structure) makes it possible for software (and users of it) to stay updated. Marking a link to a person (in the form of a website) as friend/family using the XFN markup would allow for certain types of data to be made available only to those relations. Best of all this could happen automatically. Brian Suda wrote an article on portable networks, touching on many of the same subjects.
Using OpenID could be a way of establishing a standardized (but distributed and open) identity online. In fact, it seems this is what ClaimID is all about, a site I’ve just discovered. Another very interesting project is the NoseRub protocol, an open source (MIT license) decentralized social network (also recently discovered and very similar in approach to my ideas). See also the wiki on open networking on the Microformats homepage.
I believe the combination of these existing technologies provides very promising tools of realizing the open social network, free of commercial interests and without giving away more control than absolutely necessary to make it all work. It would also seem that I either need to write a lot faster or seriously get involved in some of these projects as I discover tens of interesting resources, ideas and thoughts on the topic just be researching for these articles. Brilliant!
23 Nov 2007 - permalink
In a continuous effort to leverage the power of other sites like Flickr, I’ve integrated my Flickr photos in the blog list. Somewhat related to my thoughts on social networks and putting your content online, it is an example of pulling my data from a variety of sources and displaying them where I choose, here. It is also reminiscent of the mini feed on facebook.
Apart from spending time thinking about what I wanted, the programming didn’t take long - in great deal thanks to Zend Framework. It is my personal mashup.
I realize that most of this has already been done by software such as WordPress through it’s plugin architecture. It requires knowledge of programming and it does not include the crucial element of the social graph.
Grabbing updates from friends, however, would simply be a matter of changing the urls of the various services. As such it illustrates one of my key arguments against Facebook: The fact that Facebook is a walled garden, accessible only to members, prevents me from accessing from outside information about friends (or myself) from that small part of the internet.
Now, to solve the social graph problem…
20 Nov 2007 - permalink
Believe I just found a gem in the Database Browser bundled with TextMate! Substantially improved since I last played with it (appears to have been updated in July), it allows me to browse my local MySQL installation, looking up a table structure, browsing content or even running queries directly from my text editor.
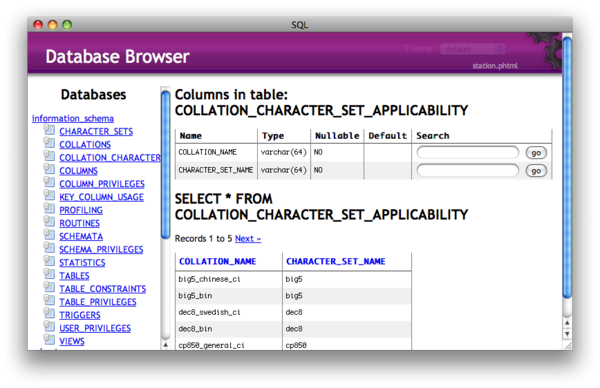
It’s not phpMyAdmin but it is definitely a context switch less in many development situations. Brilliant and - in another example of the genius TextMate is - right at my fingertips.
12 Nov 2007 - permalink
Having used 10.5 for about two weeks I must say I am very impressed. There are, however, a few things that could use a .1 upgrade. Here are a few things I’ve noticed.
-
Spotlight is very fast and returns mostly relevant results. I am disappointed that iPhoto keywords are not supported (presumably to avoid breaking the iPhoto structure). Looking for images I am thus forced to find an instance of the Media Browser.
-
Having a media browser in every Open panel is a welcome addition, with media files being organized by applications other than Finder. I wish Finder had a media browser as well.
-
Quick Look is simply an amazing tool. I wonder how I ever managed without it. Live previews on almost every file in Finder is great and very fast. Even fonts are displayed with a preview.
-
Dictionary.app has been updated with an Apple dictionary and (yay!) built-in Wikipedia! Though hardly better than the online version, it illustrates perfectly how integral part of computing the internet has become. Even better, there is now a documented way of creating new dictionaries, something I’ve requested since Tiger.
-
I love how Mail now reads my RSS feeds. Makes perfect sense to me having incoming items collected this way. I do wish I could select all feeds by clicking the RSS headline, though.
-
Web Clips (for turning parts of webpages into Widgets) is incredibly easy to use. It does not, however, store sessions making it impossible to use it on pages that require login. And I really want to use it with Google Analytics…
-
Saved Searches cannot be added to the Dock as a Stack. Would have been cool to have a stack of the 10 most recently opened documents.
-
SVG support in Safari is a great addition. Completely missing are scrollbars as well as any way of zooming. Also it would be good to have (read) support in Preview.
-
Time Machine is a beautifully easy backup tool. It does behaves erratically, however, when backing up to a disk formatted with a partition scheme not matching your CPU. It refuses to find deleted files through the Finder Spotlight search bar but reveals them by manually navigating to the relevant folder. Look at this Apple Discussions thread for more.
8 Nov 2007 - permalink
A few emails from users of my software (thank you) and my own testing has revealed that both the ShowOff screensaver and Retrospective breaks under Mac OS X 10.5.
-
ShowOff Screensaver
The screensaver refuses to run at all and crashes either System Preferences when configuring or the Screensaver Engine upon activation. Appears related to reading the preferences and loading some resources, and interestingly the preview window works. I am not entirely convinced what the cause is, but I am investigating and will hopefully have a compatible version ready soon.
-
Retrospective 1.2b3
Apple changed the caching system for Safari 3 in Leopard to make the cache and history searchable by Spotlight. While it breaks Retrospective’s ability to search the cache, it also makes it somewhat obsolete. With Spotlight finding webpages previously visited, the argument of Retrospective is moot. If you would like to see Retrospective development continued, please leave a comment or send me an email.
-
ShowOff Widget works perfectly.
1 Nov 2007 - permalink
I’ve been planning a post on what I see as the major problem with Facebook, MySpace and most other social networks: They are all walled gardens where the relations and content is kept inside the garden that is the specific site. Facebook suffers the most from this as their application interface is in effect creating a Facebook controlled internet within the internet and since profiles are only viewable by members. I have no doubt this will fail in the long run, much like AOL lost to the open nature of the web. (in spite of this Facebook was just valued at $15 billion!).
While refining my thoughts, I found a few other people also having trouble with Facebook’s closed world view. My idea was to outline the basic requirements for a social network and suggest the creation of a standard protocol for setting the social web free. I wanted to let the users be in control of their relations and content.
In many ways this would be a refinement of the APIs that many sites provide for their content. Flickr, Google and more all have APIs for interacting with the services they provide programatically. Basically, a social network is nothing more than a set of clever hyperlinks and automatic updates. I used to keep track of (online) friends by visiting their websites and reading emails. The Social API would be an open system for allowing connections between profiles on any server, allowing me to view latest blog posts, twitter updates, Flickr photos and more in a single place. Think RSS on steroids with access control.
In effect it would be an open source, distributed social network with content (dynamic hyperlinks in a way). It would need to be open source to be truly trustworthy and distributed for users to keep control of content.
Here’s a brief outline of the benefits:
- You own the domain name and choose the hosting provider.
- Content is placed with someone you trust (possibly even your own server), not some arbitrary website your friends signed up with.
- You decide who can see what and when.
- You’re always up to date on your network as updates to their content propagates to your server.
Anyway, I was preparing a list of requirements and functional outline when I read that Google is working on something that look very similar. They call it OpenSocial and according to a Macworld article their OpenSocial documentation page should be up very soon and I’ll be following this development closely.
With Google behind a social API, widespread adaption should be certain. Let’s just hope it really is open.